1Z0-034 Online Practice Questions and Answers
View the Exhibit to observe the error.
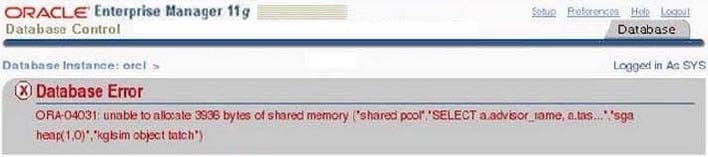
You receive this error regularly and have to shutdown the database instance to overcome the error. AutomaticShared Memory Management is configured for the instance.
What can you do to reduce the chance of this error in the future?
A. Increase the value of SGA_MAX_SIZE
B. Enable automatic memory management
C. Set the PRE_PAGE_SGA parameter to true
D. Lock the System Global Area (SGA) in memory
View the Exhibit and examine the parameter settings in your server-side parameter file (SPFILE). When you tried to start the database instance, you received the following error:
SQL> startup ORA-00824: cannot set SGA_TARGET or MEMORY_TARGET due to existing internal settings, see alert log for more information
Why did the instance fail to start?
Exhibit: A. Because the PGA_AGGREGATE_TARGET parameter is not set

B. Because the STATISTICS_LEVEL parameter is set to BASIC
C. Because MEMORY_TARGET and MEMORY_MAX_TARGET cannot be equal
D. Because both the SGA_TARGET and MEMORY_TARGET parameters are set.
You plan to use Flashback Drop feature to recover a dropped table SALES_EMP. No other table with the same name exists in the schema.
You query RECYCLEBIN and find multiple entries for the SALES_EMP table as follows: You then issue the following statement to recover the table:
SQL> SELECT object_name, original_name, droptime FROM recyclebin; What would be the outcome of the precedent statement?

A. It retrieves the latest version of the table from the recycle bin
B. It retrieves the oldest version of the table from the recycle bin
C. It retrieves the version of the table for which undo information is available
D. It returns an error because the table name is not specified as per the names in the OBJECT_NAME column
Examine the following command for RMAN backup:
RMAN> RUN {
ALLOCATE CHANNEL c1 DEVICE TYPE sbt;
ALLOCATE CHANNEL c2 DEVICE TYPE sbt;
ALLOCATE CHANNEL c3 DEVICE TYPE sbt;
BACKUP
INCREMENTAL LEVEL = 0
(DATAFILE 1,4,5 CHANNEL c1)
(DATAFILE 2,3,9 CHANNEL c2)
(DATAFILE 6,7,8 CHANNEL c3);
SQL 'ALTER SYSTEM ARCHIVE LOG CURRENT';
}
Which statement is true regarding the approach in the command?
A. The RMAN multiplexing level is 4.
B. It is the use of asynchronous I/O by RMAN.
C. It is a case of parallelization of the backup set.
D. It is an implementation of a multi section backup.
You executed the following commands:
SQL> ALTER SESSION SET OPTIMIZER_USE_PENDING_STATISTICS = false; SQL> EXECUTE
DBMS_STATS. SET_TABLE_PREFS('SH', 'CUSTOMERS', 'PUBLISH', 'false');
SQL> EXECUTE DBMS_STATS. GATHER_TABLE_STATS ('SH' , 'CUSTOMERS');
Which statement is correct regarding the above statistics collection on the SH.CUSTOMERS table in the
above session?
A. The statistics are stored in the pending statistics table in the data dictionary.
B. The statistics are treated as the current statistics by the optimizer for all sessions.
C. The statistics are treated as the current statistics by the optimizer for the current sessions only.
D. The statistics are temporary and used by the optimizer for all sessions until this session terminates.
The database users regularly complain about the difficulty in performing transactions. On investigation, you find that some users perform long-running transactions that consume huge amounts of space in the undo tablespace, which caused the problem. You want to control the usage of the undo tablespace only for these user sessions and you do not want these sessions to perform long-running operations.
How would you achieve this?
A. Implement a profile for the users.
B. Implement external roles for the users.
C. Set the threshold for the undo tablespace.
D. Implement a Database Resource Manager plan.
Your database is in NOARCHIVELOG mode.
One of the two data files belonging to the SYSTEM tablespace is corrupt.
You discover that all online redo logs have been overwritten since the last backup.
Which method would you use to recover the data file using RMAN?
A. Shut down the instance if not already shut down, restart in MOUNT state, restore both data files belonging to the SYSTEM tablespace from the last backup, and restart the instance.
B. Shut down the instance if not already shut down, restart in mount state, restore the corrupted data file belonging to the system tablespace from the last backup, and restart the instance.
C. Shut down the instance if not already shut down, restart in mount state, restore all data files for the entire database from the last backup, and restart the instance.
D. Shut down the instance if not already shut down, restart In MOUNT state, restore all data files belonging to the SYSTEM tablespace from the last backup, and restart the instance.
E. Shut down the instance if not already shut down, restart In NOMOUNT state, restore all data files for the entire database from the last backup, and restart the instance.
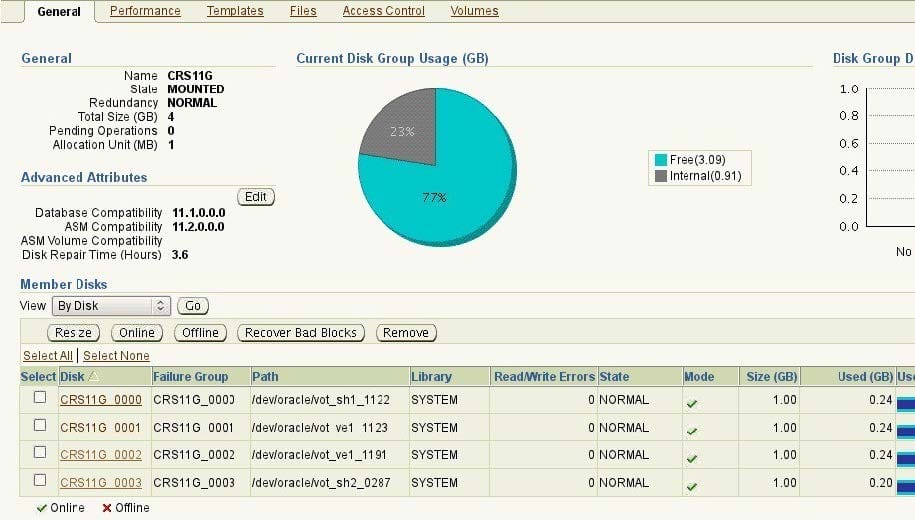
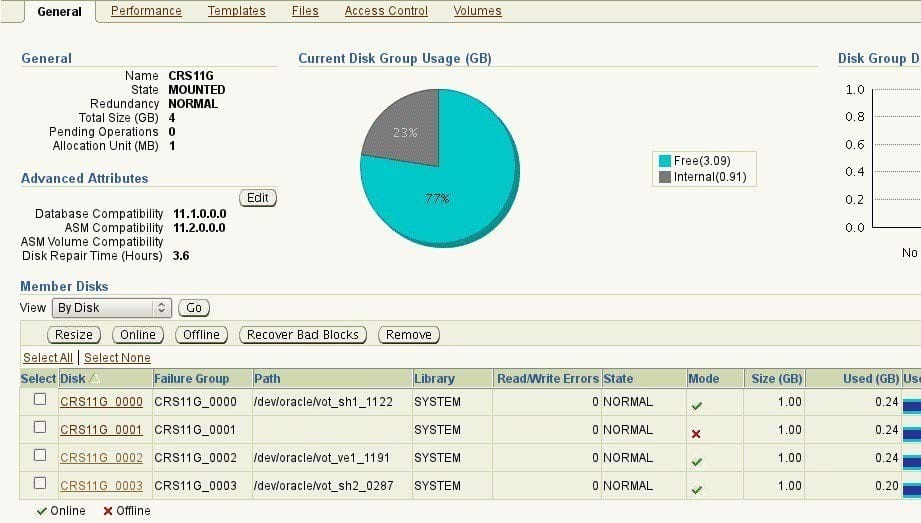
View Exhibit1 to examine the CRS11G disk group when all the disks are online. View Exhibit2 to examine
the CRS11G disk group when one disk is offline.
Why is the rebalancing not performed and the content of the disk group not empty in Exhibit2?
ASM-disk-group-1 (exhibit):
ASM-disk-group-2 (exhibit): A. Because the disk group is created with NORMAL redundancy
B. Because the disk repair time attribute is set to a nonzero value
C. Because the mirrored extents cannot be rebalanced across the other three disks
D. Because the other three disks have 60% free space, the disk rebalancing is delayed
Why select/choose certbus.com?
Millions of interested professionals can touch the destination of success in exams by certbus.com. products which would be available, affordable, updated and of really best quality to overcome the difficulties of any course outlines. Questions and Answers material is updated in highly outclass manner on regular basis and material is released periodically and is available in testing centers with whom we are maintaining our relationship to get latest material.
![]()
![]()
Copyright © 2004-2025 certbus.com, All Rights Reserved.